「AWS上にマラソンマッチ用のジャッジ環境を作った」をChatGPTに投げて、Lambdaを使ったAHC用のジャッジ環境を作る。
概要
Webやサーバー関係に詳しくなくても、良い記事をChatGPTに投げればなんとかなる。
ChatGPTのいいなりになればOK
AtCoder Heuristics Contest(AHC)用にAWS Lambdaを使った自作ジャッジを作りたいなと思っていたので重い腰を上げましたがその辺の知識はありません。そこでyunixさんの素晴らしい記事を発見します。
yunix-kyopro.hatenablog.com
AWSを触ったことがない人向けには書いていないです。すいません...
と書いてありますが、気にせず上記の記事をコピペしてChatGPTに丸投げします。

以下のようにコマンドつきで基本的な部分から手取り足取り教えてくれます。

Ubuntuでも出来ますか?レベルの質問でもChatGPTは丁寧に回答してくれます。

あとは、「エラーが出たら、エラーログを添付して質問」「ハマったら原因を適当に推測してもらう」を繰り返すと、自分用のジャッジが作れます。詳しく勉強したい部分があったらそれも質問するといいです。
以下が実行結果です。できました。yunixさんありがとうございます。

はまったところ
typescriptを使った設定にする必要があった。
CDK(AWS Cloud Development Kit )はpythonやtypescriptで設定できますが、記事に載っていたのはtypescriptだったので質問しなおしました。

リージョン間違いでログが何も見れなかった…
エラーログやLambdaの各種情報は何も設定しなくても表示されます。出てなければ何かおかしいです。この手の問題があると何が起こっているかさっぱり分からないので最初に直しましょう。ChatGPTはひどい勘違い系も割とヒントをくれるのが良いです。

ログを見る場合はhttps://console.aws.amazon.comにCloudWatchを追加すると見れます。python内でprintで標準出力したものもここで見れます。特別な設定はいりませんがリージョンを間違えていると何も見れません。


ジャッジ環境のディレクトリ構成が分からなかった。


記事に載っている1つ目のtypescriptはlib以下に置きます。

記事に載っている2つ目のDockerfile, 3つ目のhandlers.pyはlambda以下に置きます。また、requirements.txt(空ファイルで良い)も置く必要があります。

なお、main.cppやAHCのテスターを置くコンテスト毎のディレクトリとは別のものです。記事に載っている4つ目のpythonスクリプトは、コンテスト毎のディレクトリからmain.cppをS3に送ったりするのに使います。
別なバケット名を設定していた。
元の記事のpython実行スクリプトが以下のようになっているので、"バケット名"を書く必要があります。

バケットは2つ出来ているかもしれませんが、marathonjudge~のほうを設定します。もう一方のcdk-~はAWS CDKが、AWS CDK自体が管理するためのバケットの名前です

各種パスの更新をわすれていた
handlers.pyを実行したら、cdk deployコマンドでデプロイしなおすのも忘れないでください。
# handlers.py import os import json import boto3 def entry_handler(event, context): timestamp = event["timestamp"] contest_name = event["contest_name"] N = 50 result = [ { "test_path": f"{contest_name}/in/{i:04}.txt", # 要変更。テスト用入力ファイルのパス "timestamp": timestamp, "contest": contest_name, "id": f"{i:04}" } for i in range(0, N, 1) ] return {"tasks": result} def exec_handler(event, context): print(event, os.environ["s3Bucket"]) # 前の段からテストファイルのパス・コンテスト名を取得 test_path = event["test_path"] contest_name = event["contest"] test_id = event["id"] timestamp = event["timestamp"] # ソースコードを取得してビルドする bucket = boto3.resource("s3").Bucket(os.environ["s3Bucket"]) bucket.download_file(f"{contest_name}/main.cpp", "/tmp/main.cpp") # {contest_name}/main.cpp。ここは記事に載っている4つめのスクリプトを使えばこのままで良い。 os.system("g++ -O2 /tmp/main.cpp -o /tmp/a.out") # スコア計算のスクリプトを取得 bucket.download_file(f"{contest_name}/vis", "/tmp/vis") # 要変更。テスター。{contest_name}/visは、S3で自分で設置した場所を指定。visは"cargo run --release --bin vis"でRustコンパイルしておく。 os.system("chmod 777 /tmp/vis")
同時実行数が最大で10になっていた。
TooManyRequestsExceptionというエラーがよくかえってきたのですが、50個のテストケースを回していたのに最大10だったからでした。デフォルトで1000らしいですがなぜか10になっていました。

最後にChatGPTによるブログ

タイトル: AWS LambdaとAmazon S3を使用した高負荷タスクの並列化
AWS LambdaとAmazon S3を組み合わせることで、高負荷タスクを並列化し、処理効率を向上させることができます。今回は、プログラミングコンテストのジャッジシステムを構築する例として、AWS CDKとAWS Step Functionsを使って、この組み合わせを実装する方法を解説します。
1. AWS CDKとLambda関数の作成
まず、AWS CDKを使用して、タスクの各ステージを処理するLambda関数を作成します。今回は、各問題を別々に評価するためのLambda関数(evaluation-lambda)、評価結果をまとめるためのLambda関数(summary-lambda)、それらを制御するエントリポイントとなるLambda関数(entry-lambda)の3つを作成します。Lambda関数は、AWS CDKのlambda.DockerImageFunctionを使用してDockerイメージから作成します。
各Lambda関数はS3バケットに対する読み書き権限を持ち、バケット名は環境変数から取得します。
2. Step Functionsの構築
次に、AWS Step Functionsを使用してこれらのLambda関数を連携させます。Step Functionsのステートマシンは、エントリポイントのLambda関数を最初に実行し、次にマップステートを使用して評価Lambda関数を並列実行し、最後に結果をまとめるLambda関数を実行します。
3. ログの確認
Lambda関数がエラーを返す場合や、デバッグが必要な場合は、AWS CloudWatch Logsを使用してログを確認できます。CDKで作成したLambda関数は、関数名が自動生成されるため、AWS Management ConsoleのLambdaのダッシュボードから関数を見つけることができます。
4. バケットとファイルパスの確認
Lambda関数がS3からファイルをダウンロードできない場合、バケット名やファイルパスが正しいか確認が必要です。S3バケットの名称はCDKスタック名とリソース名から自動生成されるため、AWS Management Consoleから確認することができます。
5. 同時実行数の調整
Lambda関数の同時実行数が多すぎる場合、TooManyRequestsExceptionが発生する可能性があります。これは、Lambda関数のデフォルトの同時実行数(1000)を超えた場合や、Lambda関数の設定で制限された場合に発生します。
解決方法としては、AWS Management ConsoleのLambdaの設定から特定のLambda関数の同時実行数の上限を増やす方法があります。さらに、Lambda関数の上限がアカウントレベルで設定された上限("予約されていない同時実行数")を超えている場合は、AWSサポートに問い合わせてアカウントレベルの同時実行数の上限を増やすことも必要です。
今回の実装を通して、AWS LambdaとAmazon S3を組み合わせて、高負荷タスクを効率的に並列化する方法を学びました。この方法は、プログラミングコンテストのジャッジシステムだけでなく、データ処理やマイクロサービスの構築など、さまざまなシナリオで応用できます。
「競技プログラミングの鉄則」のレビュー
米田 優峻さん(E869120@ICPC2022 (@e869120) / Twitter)の著書「競技プログラミングの鉄則 ~アルゴリズム力と思考力を高める77の技術~」をご恵贈いただきました。その感想です。
")
素晴らしい内容で競技プログラミング初心者への最初の1冊として最もお勧めできる本です。特に、数学も得意というわけではなくプログラミング自体も初めてという方には、ダントツで一番お勧めできる本です。
本書の良い点
1.図が分かりやすい。
最初の48ページが無料公開されているので、百聞は一見にしかずということで見ていただけると良いと思います。i
www.dropbox.com
図自体分かりやすいですし全編カラーで書かれているのも良いです。段階的に説明すべきものについて無理に1枚に納めず多くの小さい図に分けて説明しているのもとても分かりやすいです。先ほどのpdfにある図の1つです。
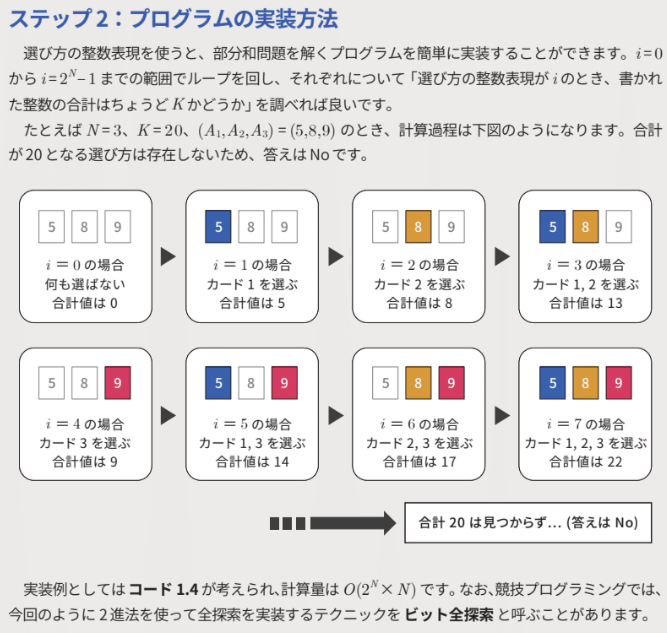
また、既に理解しているアルゴリズムでも、勘違いしたりケアレスミスしたり書くのに妙に時間かかったりすることは誰にでもあると思います。本書の分かりやすい図は、自分の中での理解をアップデートするのにとても役立ちました。簡単な問題でも「あー、たしかにこういうふうにイメージできれば、すっきり理解できるなぁ」と感じることが多かったです。
2.つまづきにくい。
頭が良いが説明が苦手な人が記事を書くと、説明の段差が大きくなりがち(例: 「自明である」、「定義そのもの」、式の省略等)ですが、この本についてはそういうことはありません。特に、各節最初の例題は「無駄な部分を省き、学んでほしい部分に絞った問題」となっており、その例題まですら図で多く説明しているので、とにかく最初の1歩では絶対につまづかせないという意図を感じます。続く応用問題もほとんどの場合は例題に沿っています(でもコピペではうまくいかないちょうど良い問題)。必要に応じてヒントも書かれています。つまづきにくいです。

3.ヒューリスティックスについて取り上げてある。
できるだけ良い答えを出す系のコンテストAHC(AtCoder Heuristics Contest)についてはネットの記事はあるのですがまとまっているわけではないので、体系的に学びたい初めての人にこの本はとても良いと思います。貪欲法→局所探索法(単純山登り)→焼きなまし法のように、実際のコンテストで徐々にコードを改善していく過程に沿って書かれているので、コード量が増えがちでも分かりやすいと思います。
4.考察テクニックの章
問題のパターンは無数にあり全解法覚えるわけにもいかず自力で考察するほうが本質だと思うのですが、その考察について1章分設ける(6章)*1はとても良いと思いました。考察テクニックはもっとあると思うので、もしこの本の続編がでる場合は、さらにこの部分の分量をふやしてもらえると嬉しいです。
5.コンテンツが充実
まず問題集151問がすべてAtCoder上で利用できます。
atcoder.jp
本に載っていない分についてはgithubが用意されており、C++, Java, Pythonの3言語での解答コードも読むことができます。親切です。
github.com
解説pdfについても、本書程ではないにせよ図を駆使して分かりやすく書かれており、全216ページ(!)もあります。付録コンテンツは誰でも無料で利用できるのですが、正直ここだけでも商品になる気がします…。
本書の賛否両論ありそうな点
コードの書き方
分かりやすさのために一般プログラミングの作法については目をつむる、他の本で勉強してね、という方針は構わないと思いますが、以下の2つは気になりました。
- 変数の定義がmainの関数内で行われている場合と関数外で行われている場合があり、その理由が特に書かれていない。
- スタックオーバーフローを避けるために全部外に書きグローバル変数とするというのであればある意味分かりますが、そうでない例もあります。
- STLに関して、説明無しで登場しているところがある(3.5章 vector)
- ここまで引っ張るより早めにどこかでSTLについて説明したほうが、生配列よりもvectorのほうが良い部分で素直にvectorを使えたので良かったかもしれません。
親切すぎる
裏を返すと、この本に慣れると
- コンテストにでる、あまり素直でない問題
- 一足飛びの解説
などの耐性があまり付かず今後つまづくかもしれません。ただ、終章で次の教材として勧めている「競プロ典型90問」については「解説は原則1ページで簡潔にまとめられているため、分かりづらい部分もあるかもしれません。しかし、解説の行間を読むのも練習です。」と述べられており、この鉄則本については割り切って超親切にしているのかなと思いました。
同じジャンルでまとまっていて、必ずしも難度順にはなっていない。
同じジャンルのものをまとめる方式になっており、他の本では最初の方に来る「深さ優先探索」「幅優先探索」はグラフなので本書では最後のほうの9.2章・9.3章に主に取り上げています。ただ、この本は十分にわかりやすく、勉強の際には飛ばして必要な章から読むことも可能なので、必要なら飛ばし読みして良いと思います。
難度と勉強時間の目安
YouTubeで生放送しながら、本書を全部読み演習問題集の全151問を解いたのですが、33時間46分43秒かかりました。そのときの生放送は全てYouTubeのプレイリストにまとめてあります。
www.youtube.com
喋りながら問題を解くとだいぶ遅くなるのも踏まえると、おそらくAtCoder水色レベルの人なら20~25時間で全部読んで全問解けるのではないでしょうか?勉強する際の時間の目安として参考にしていただければと思います。
また著書の最終章にも書かれているのですが、米田優峻さんが本書の次にお勧めしている「競プロ典型90問」について現在解いていっています。こちらも良問が多くこれらも全て解説スライドがあり、とても親切です。
atcoder.jp
おわりに
そういうわけで自信を持ってお勧めできる本なので、みなさん購入しましょう!また、個人的な話ですが、この本がきっかけで毎朝7:00からの競プロ学習習慣がついた気がするので、このまま続けていきたいと思っています。
*1:10章の最初にも考察テクニックが書かれてあります
焼きなまし法のコツ Ver. 1.3
焼きなまし法そのものの解説は少しだけにして、焼きなまし法の使い方のコツをメインに書こうと思います。
焼きなまし法の概要
最適化(=最大値か最小値を求める)の手法の1つです。以下は擬似コードです。
あらかじめ、計算する時間を決める。
以下のスコープ内のコードを時間経過するまで繰り返す。
{
適当に、次の状態(近傍)を選ぶ。
(1) 次の状態のスコアが、今の状態のスコアより良くなった場合は、常に、状態を次の状態にする(遷移)。
(2) 次の状態のスコアが、今の状態のスコアより悪くなった場合でも、ある確率で、状態を次の状態にする。
確率は以下のように決める。
(2.A) 序盤(経過時間が0に近いとき)ほど高確率で、終盤ほど低確率。
(2.B) スコアが悪くなった量が大きければ大きいほど、低確率。
}
最後に、今までで一番スコアのよかった状態を選ぶ。
次の状態が悪くてもそれを選ぶ可能性がある(2)の部分が、焼きなまし法の最大の特徴です。
「状態」「スコア」というのがピンとこないかもしれませんが、
- もし、巡回セールスマン問題であれば、
- 状態 →ルート
- 次の状態(近傍)→元のルートをちょっとだけかえてみたルート
- スコア →総距離
- もし、y=f(x)の最大値を求める問題であれば、
- 状態 →x
- 次の状態(近傍)→ x' = x + a (aは小さめの値)
- スコア →y
といったかんじです。
サンプルソースコード
AtCoderのコンテストIntroduction to Heuristics Contest - AtCoderで、スケジューリング問題が出題されました。 この問題は焼きなまし法が効果的です。C++でのサンプルを2つ用意しました。変数名は問題に合わせています。
サンプル1
単純な焼きなまし法。1165人中400位相当の解法です。焼きなまし法の本質は、// 焼きなまし法(ここから)の部分です。
AtCoderの提出コード
ソースコードを開く
#include <iostream> #include <vector> #include <algorithm> #include <chrono> #include <cassert> #include <climits> #include <cmath> using namespace std; using namespace chrono; // 0以上UINT_MAX(0xffffffff)以下の整数をとる乱数 xorshift https://ja.wikipedia.org/wiki/Xorshift static uint32_t randXor() { static uint32_t x = 123456789; static uint32_t y = 362436069; static uint32_t z = 521288629; static uint32_t w = 88675123; uint32_t t; t = x ^ (x << 11); x = y; y = z; z = w; return w = (w ^ (w >> 19)) ^ (t ^ (t >> 8)); } // 0以上1未満の小数をとる乱数 static double rand01() { return (randXor() + 0.5) * (1.0 / UINT_MAX); } const static int NUM_TYPES = 26; // コンテストの種類数 // 全体のスコア(今回の問題のスコア) static int getFullScore(const int D, const vector <int>& C, const vector <int>& T, const vector<vector<int>>& S) { int score = 0; vector <int> last(NUM_TYPES, 0); for (int d = 0; d < D; d++) { const int j = T[d]; last[j] = d + 1; for (int t = 0; t < NUM_TYPES; t++) { score -= (d + 1 - last[t]) * C[t]; } score += S[d][j]; } return score; } int main() { // 入力 int D; cin >> D; vector<int> C(NUM_TYPES); for (int &c : C) { cin >> c; } vector<vector<int>> S(D, vector<int>(NUM_TYPES)); for (auto &s : S) for (auto &x : s) { cin >> x; } // 初期解 vector<int> T(D); // T[d] d日目に開くコンテスト for (int d = 0; d < D; d++) { T[d] = d % NUM_TYPES; } // 焼きなまし法(ここから) auto startClock = system_clock::now(); int score = getFullScore(D, C, T, S); // 現在のスコア int bestScore = INT_MIN; // 最高スコア vector <int> bestT; // 最高スコアを出したときのT const static double START_TEMP = 1500; // 開始時の温度 const static double END_TEMP = 100; // 終了時の温度 const static double END_TIME = 1.8; // 終了時間(秒) double time = 0.0; // 経過時間(秒) do { const double progressRatio = time / END_TIME; // 進捗。開始時が0.0、終了時が1.0 const double temp = START_TEMP + (END_TEMP - START_TEMP) * progressRatio; // 近傍 : d日目のコンテストをtに変えてみる。d,tはランダムに選ぶ。 const int d = randXor() % D; const int t = randXor() % NUM_TYPES; const int backupT = T[d]; int deltaScore = 0; // スコアの差分 = 変更後のスコア - 変更前のスコア deltaScore -= getFullScore(D, C, T, S); T[d] = t; // 変更 deltaScore += getFullScore(D, C, T, S); const double probability = exp(deltaScore / temp); // 焼きなまし法の遷移確率 if (probability > rand01()) { // 変更を受け入れる。スコアを更新 score += deltaScore; if (score > bestScore) { bestScore = score; bestT = T; } } else { // 変更を受け入れないので、元に戻す T[d] = backupT; } time = (duration_cast<microseconds>(system_clock::now() - startClock).count() * 1e-6); } while (time < END_TIME); // 焼きなまし法(ここまで) // 出力 for (int t : bestT) { cout << t + 1 << endl; } cerr << "bestScore: " << max(0, bestScore + 1000000) << endl; return 0; }
サンプル2
やや複雑ですが、かなり改善した焼きなまし法。1位相当の解法です。
AtCoderの提出コード
ソースコードを開く
#include <iostream> #include <vector> #include <algorithm> #include <chrono> #include <cassert> #include <climits> #include <cmath> using namespace std; using namespace chrono; // 0以上UINT_MAX(0xffffffff)以下の整数をとる乱数 xorshift https://ja.wikipedia.org/wiki/Xorshift static uint32_t randXor() { static uint32_t x = 123456789; static uint32_t y = 362436069; static uint32_t z = 521288629; static uint32_t w = 88675123; uint32_t t; t = x ^ (x << 11); x = y; y = z; z = w; return w = (w ^ (w >> 19)) ^ (t ^ (t >> 8)); } // 0以上1未満の小数をとる乱数 static double rand01() { return (randXor() + 0.5) * (1.0 / UINT_MAX); } const static int NUM_TYPES = 26; // コンテストの種類数 // 全体のスコア(今回の問題のスコア) static int getFullScore(const int D, const vector <int>& C, const vector <int>& T, const vector<vector<int>>& S) { int score = 0; vector <int> last(NUM_TYPES, 0); for (int d = 0; d < D; d++) { const int j = T[d]; last[j] = d + 1; for (int t = 0; t < NUM_TYPES; t++) { score -= (d + 1 - last[t]) * C[t]; } score += S[d][j]; } return score; } // d日目のコンテストT[d]を開いたときのスコア増分 static int getContestScore(const int d, const int D, const vector <int>& C, const vector <int>& T, const vector<vector<int>>& S) { const int t = T[d]; int score = S[d][t]; int prev = d - 1; // d日目以前に開かれる同じコンテストの日 while (prev >= 0 && T[prev] != t) { prev--; } int next = d + 1; // d日目以降に開かれる同じコンテストの日 while (next < D && T[next] != t) { next++; } // sum(x) = x*(x+1)/2 つまり1,2...,xまでの等差数列の和とすると // score -= sum(next - prev -1) * (-C[t]); // ... (1) // score += sum(day - prev -1) + sum(next - day -1) * (-C[t]); // ... (2) // p---------n コンテストをおく前 // 123456789 // ... (1) // p---d-----n コンテストをおいた後 // 123 12345 // ... (2) score += (next - d) * (d - prev) * C[t]; // (1)と(2)を計算すると、簡単になる。 return score; } int main() { auto startClock = system_clock::now(); // 入力 int D; cin >> D; vector<int> C(NUM_TYPES); for (int &c : C) { cin >> c; } vector<vector<int>> S(D, vector<int>(NUM_TYPES)); for (auto &s : S) for (auto &x : s) { cin >> x; } vector<int> T(D); // T[d] d日目に開くコンテスト for (int d = 0; d < D; d++) { T[d] = d % NUM_TYPES; } int score = getFullScore(D, C, T, S); // 現在のスコア int bestScore = INT_MIN; // 最高スコア vector <int> bestT; // 最高スコアを出したときのT const static double START_TEMP = 1500; // 開始時の温度 const static double END_TEMP = 100; // 終了時の温度 const static double END_TIME = 1.8; // 終了時間(秒) double temp = START_TEMP; // 現在の温度 long long steps; // 試行回数 for (steps = 0; ; steps++) { if (steps % 10000 == 0) { const double time = duration_cast<microseconds>(system_clock::now() - startClock).count() * 1e-6; // 経過時間(秒) if (time >= END_TIME) { break; } const double progressRatio = time / END_TIME; // 進捗。開始時が0.0、終了時が1.0 temp = START_TEMP + (END_TEMP - START_TEMP) * progressRatio; } if (rand01() > 0.5) { // 近傍1 : d日目のコンテストをtに変えてみる const int d = randXor() % D; const int t = randXor() % NUM_TYPES; const int backupT = T[d]; int deltaScore = 0; // 変更前のd日目のコンテストのスコアを引き、変更して、変更後のコンテストのスコアtを足す。 deltaScore -= getContestScore(d, D, C, T, S); T[d] = t; deltaScore += getContestScore(d, D, C, T, S); const double probability = exp(deltaScore / temp); // 焼きなまし法の遷移確率 if (probability > rand01()) { // 変更を受け入れる。スコアを更新 score += deltaScore; if (score > bestScore) { bestScore = score; bestT = T; } } else { // 変更を受け入れないので、元に戻す T[d] = backupT; } } else { // 近傍2 : d0日目のコンテストとd1日目コンテストを交換してみる const int diff = randXor() % 10 + 1; // d0とd1は10日差まで const int d0 = randXor() % (D - diff); const int d1 = d0 + diff; int deltaScore = 0; // 変更前のd0日目とd1日目のコンテストのスコアを引き、変更後のd0日目とd1日目のコンテストのスコアを足す deltaScore -= getContestScore(d0, D, C, T, S); deltaScore -= getContestScore(d1, D, C, T, S); swap(T[d0], T[d1]); deltaScore += getContestScore(d0, D, C, T, S); deltaScore += getContestScore(d1, D, C, T, S); const double probability = exp(deltaScore / temp); // 焼きなまし法の遷移確率 if (probability > rand01()) { // 変更を受け入れる。スコアを更新 score += deltaScore; if (score > bestScore) { bestScore = score; bestT = T; } } else { // 変更を受け入れないので、元に戻す swap(T[d0], T[d1]); } } } // 出力 for (int t : bestT) { cout << t + 1 << endl; } cerr << "steps: " << steps << endl; cerr << "bestScore: " << max(0, bestScore + 1000000) << endl; return 0; }
焼きなまし法のコツ
★が多いほど、重要だと思っています。
1. 高速化
試行回数が多いほど、スコアが伸びる可能性があります。基本的にはボトルネックを調べて、そこを高速化しましょう。だいたい以下のところがボトルネックになるでしょう。
★★★★ プロファイルして、計算時間がかかっているボトルネックを探す
2021/03/06 追加しました。
焼きなまし法に限らず、マラソンマッチに限らず、プログラミング一般であらゆる高速化の前にやるべきことです。プロファイルの仕方はOSやツールにより違いますが、例えばVisual Studioなら「デバッグ」→「パフォーマンス プロファイラ」で、一発でできます。思わぬところがボトルネックになってることも多いので、絶対しましょう。

★★★★ 高速化がどれだけ効果的か検討する。
重要です。ためしに10秒だけやってる計算を、あえて100秒とかに伸ばしてみて、結果がどうなるか見てみましょう。
- 時間をかければかけるほどスコアが伸びる
- 高速化しよう&スコアが素早く伸びるように次の状態を決めよう。山登り法に変えるのも良い。
- 時間をかけてもスコアが伸びない & スコアが高い
- 最適解がでてる可能性が高い。計算を打ち切って、余った時間を他に使う
- 時間をかけてもスコアが伸びない & スコアが低い
- 次の状態の決め方、スコア関数の見直しを再検討する。焼きなまし法を使わない法がよいときもあるのも忘れずに。
こういった実験は自分のPCで行うわけなので、並列化などを行い計算リソースも存分に使ってよいです。
★★★★ 変更がある変数だけを保存して、戻す
先ほどのコードだと、
const int backupT = T[d]; // (略) { // 変更を受け入れないので、元に戻す T[d] = backupT; }
の部分です。変更した、T[d]の部分だけをバックアップしておけば、元に戻せます。T全体を保存する必要はありません。
★★ 逆の手で、戻す
逆の手をやれば、前の状態に高速に戻せるのであれば、そうしましょう。例えば、上下左右に駒をうごかせるというパズル問題であれば、左に動かした後であれば、右に動かせば、戻せます。また、2つをswapするといった場合は、もう1回swapすれば戻せます。
★★★★ スコア関数の高速化
スコア関数の求め方は問題によって大きく異なるので、計算時間も異なってきます。ボトルネックになってたら高速化しましょう。
また、スコア関数の正確さを犠牲にしてでも、高速化したほうが良い場合もあります。1つのコツとして覚えて置きましょう。
★★★★ スコア差分計算時の打ち切り
2021/03/06 追加しました。
スコア差分計算の途中で、差分がすでに大きくマイナスになっていて、もうその後計算し続けていても絶対に遷移の受理確率がほぼ0っぽいのであれば、差分計算を打ち切って高速化することができます。焼きなまし法は遷移が成功するケースより遷移が失敗するケースが多く、失敗するケースをさっさと打ち切ることができれば高速化につながることが多いです。
また問題によっては、スコア差分の上界・下界が分かるケースもあり、これらが短時間で求められるのであれば、それもスコア差分計算の打ち切りに使用可能です。例えば、Google Hash Code 2021の練習問題では、10000ビットのORを取り、(ビットが1の数)の2乗がスコアになる問題がありました。10000ビットのORはそれなりに時間がかかりますが、
(ほんとは10000ビットある)
1110010101001 (1が7個) 0011000101000 (1が4個) ↓ OR 1111010101001 (1が9個。つまり81点)
と実際にORをとらずとも、
1110010101001 (1が7個) 0011000101000 (1が4個) ↓ OR ??????????????? (1が最小で7個、最大で11個、つまり49点~121点のあいだ)
というのが分かれば、打ち切り時の計算の参考になります。
★★★ 状態を変えずにスコア差分を計算する
2021/03/06 追加しました。
状態の更新をする部分がボトルネックとなっている場合は、
サンプル2の以下のような書き方よりも、
状態を変える 差分スコアを求める 遷移確率probabilityを求める if (probability > rand01()) // 遷移条件を満たすか { // 変更を受け入れる。スコアを更新 } else { // 変更を受け入れないので、状態を元に戻す }
以下のような形のほうが良いです。なぜなら状態遷移しないときに状態更新の計算を省けるからです。また、スコア差分計算時の打ち切りを行う際も、打ち切った際に状態を戻す必要がないため、この形のほうが恩恵が大きいです。
状態を変えずに差分スコアを求める 遷移確率probabilityを求める if (probability > rand01()) // 遷移条件を満たすか { // 変更を受け入れる。スコアを更新。状態も更新 }
ただ、短時間で書けるほうは大抵サンプル2の形なので、まずはサンプル2の形で書いて、その後この形に持っていくのが良いと思います。
★★ C言語のrand()を使わない。
C言語のrand()は遅いので、高速なxor128を使いましょう。
unsigned int randxor() { static unsigned int x=123456789,y=362436069,z=521288629,w=88675123; unsigned int t; t=(x^(x<<11));x=y;y=z;z=w; return( w=(w^(w>>19))^(t^(t>>8)) ); }
★ 時間計測の関数を呼びすぎない。
サンプル2のように、10000回に1回だけ時間計測をするという方法があります(時間計測の関数はsystem_clockを使えば近年は十分速いですが)。時間計測以外の値でも、毎回計算する必要がないものがあればここで計算してしまいましょう。
long long steps; // 試行回数 for (steps = 0; ; steps++) { if (steps % 10000 == 0) { const double time = duration_cast<microseconds>(system_clock::now() - startClock).count() * 1e-6; // 経過時間(秒) if (time >= END_TIME) { break; }
ただ、TopCoderだとこの回数を増やしすぎて、制限時間オーバーしてしまうという可能性もあります。そういった点も考えて、適切な回数おきに時間をはかるようにしましょう。残り時間が少なくなったら、ループ回数を減らすといった安全策をとる方法もあります。
2. 次の状態(状態近傍)をどう決めるか?
ここは鍵になる部分ですが、コツとしてまとめるのは難しいところですね…。
★★★★ スコアが改善しやすくなるように、次の状態を選ぶ。
これは、問題ごとによく考えて対処しなければいけないので、あまり「コツ」というかんじではないのですが…。
[問題] タスク数aの仕事Aと、タスク数bの仕事Bがある。 作業員はx人いて、それぞれ、1時間あたりにこなせる仕事Aのタスク数と、仕事Bのタスク数は決まっている。 ただし、仕事Aの仕事Bのどちらかしか行うことができない。 仕事Aと仕事Bの両方が終わるのに時間が最小になるように、作業員を仕事Aか仕事Bのどちらかに割り当てよ。
焼きなまし法で解くなら、まず最初にてきとーに作業員をA,Bに割り振り、ここからスコア=作業時間として、改善させていきます。こういった問題を解くときに、次の状態として以下の2つを考えてみましょう。
- 移動:ある作業員をA→B または B→A に移動させる。
- 交換:Aの作業員の誰かと、Bの作業員の誰かを交換する。
移動2回は交換になることもあるので、とりあえず移動をさせておけば、交換もたまにしてくれるし良さそうに見えますが、そうとは限りません。この場合は、交換を主に行い、たまに移動させるぐらいがちょうど良いと思います。移動では、人数が偏り、片方の仕事の作業時間が増えやすくなります。2回移動すれば、交換になって、作業時間が減る可能性がありますが、
- 移動:良スコア → 悪いスコア → とても良いスコア
- 交換:良スコア → とても良いスコア
と考えると、移動だけだと、スコアが悪い状態を経由しないとダメなので、運がよくないと、とても良いスコアまで辿りつけません。その点、交換ならば、人員が偏った悪いスコアになりやすい状態をスキップできるので、スムーズにとても良いスコアまで改善できます。
もちろん、正しい人数割り当てもしなければいけないので、移動も少しは試したほうがいいですが、こういった点も考えて次の状態を決めると、スコアが改善しやすくなります。
★★★★ 近傍の種類を増やす
2021/03/06 追加しました。
近傍の種類は多くあればあるほど良いです。上記のサンプル2のコードには、近傍が2種類用意されています。
// 近傍1 : d日目のコンテストをtに変えてみる const int d = randXor() % D; const int t = randXor() % NUM_TYPES;
// 近傍2 : d0日目のコンテストとd1日目コンテストを交換してみる const int diff = randXor() % 10 + 1; // d0とd1は10日差まで const int d0 = randXor() % (D - diff); const int d1 = d0 + diff;
サンプル2では、近傍1も近傍2も50%ずつの確率で選んでいますが、ここをどの近傍をどれぐらいの確率で試すかを調整すれば、性能を改善できるチャンスがあります。また、統計をとるのも大事です。遷移が成功した回数・失敗した回数のデータを取っておけば、どの近傍が有効なのかが分かり、問題を理解するヒントにもなります。さらに、「近傍1で遷移が成功すると、その直後で近傍2で遷移が成功しやすい」などの事実が分かれば、あらたに近傍3「近傍1のあとに近傍2」という新たな近傍を用意することもできるでしょう。
★★ Greedyに、次の状態を選ぶ。
先ほどの問題であれば、「仕事Aと仕事Bそれぞれから、常に作業時間が一番多くかかっている人を1人ずつ選び、交換」とGreedyに、次の状態を選ぶことができます。こういう選び方をすると、ベストスコアは序盤はどんどん伸びていきますが、局所最適に陥りやすいです。また、ありがちなのが、Greedyに選ぶアルゴリズムが、計算時間のボトルネックになってしまうパターンです。複雑なアルゴリズムより、ランダムでとにかくいろいろ試すのが焼きなまし法の強みです。Greedyにやるにせよ、多少ランダムを入れたり、計算時間はかからない単純な選び方をしたりする工夫が必要です。
★★ 序盤は大きく変化、終盤は小さく変化させたほうがいい。
単純にy=f(x)のyを最大化する問題なら、
- 序盤(t=0に近いとき) 次のx'は x'=x+rand()%1001 - 500
- 終盤(t=Tに近いとき) 次のx'は x'=x+rand()% 11 - 5
とか、
作業員割り当ての問題なら、
- 序盤(t=0に近いとき) 交換を100回やる
- 終盤(t=Tに近いとき) 交換を 1回やる
といったかんじです。スコアが局所最適でハマっている場合は有効です。ただ、焼きなまし法自体が、局所最適にはまりにくいアルゴリズムなので、あまり効果がない場合も多いです。
★★★★ 状態が大きく変化するわりには、スコアが変わらない近傍は良い。
2021/03/06 追加しました。
- 状態変化が大きいけど、スコアが大きい変化しかしない(悪化する確率が圧倒的に高い)
- 状態変化が小さいけど、スコアが小さい変化しかしない近傍
となりがちなのですが、問題によっては状態が大きく変化するわりには、スコアがあまり変化がしないケースがあります。こういう近傍があると、遷移が小さい近傍だけは辿りつけない状態にも短時間で行くことができ、焼きなましの性能がアップします。見逃さないようにしましょう。
★★★ 初期状態からすべての状態に行けるようにする。
2021/03/06 追加しました。
選んだ初期状態によっては、どんなに運がよくても用意した近傍ではすべての状態に辿りつけない場合があります。特に解に制約条件があるような問題(例:パズル問題など)で、このようなことが起こりやすいです。すべての状態にいけるような近傍を用意しましょう。
- 無理にランダムに大きく状態が変化するような近傍を入れてしまうと、それ自体が遷移の成功確率を大きく減らすことにもなり、全体の性能を落とす可能性があるので、簡単ではありません。
- 多点スタート(後述)にすれば、ある程度緩和されますが、多点スタートでは1つの解を求めるのにかけられる計算時間が減ってしまい、あまりよくありません。
- スコア関数にペナルティ(後述)を入れる方法もあります。
★★ 良い初期状態からスタートする
これは問題に大きく依存する項目です。初期状態はてきとーでも良い場合と、すこし時間をかけて計算して良い状態から始めたほうが良い場合があります。特に、初期状態が悪いと状態を改善する近傍の選択肢が少なすぎる、逆に言えば、状態を改善すればするほどさらに改善できる可能性が増えるタイプの問題は、初期状態に少し時間を書けて求めて、それから焼きなましたほうが良い結果がでる場合があります。
3. スコア関数
スコア関数(scoring function)とも、評価関数(evaluation function)とも呼びます。
★★★★★ 良い状態を正しく評価できるような、スコア関数を新たに用意する
問題のスコア関数をそのまま使うと、焼きなまし法がうまく行かないことがあります。良い状態を正しく評価できるような、新たなスコア関数を用意しましょう。
[問題] (大きく略)… i番目の人の満足値をs(i)とする。「満足度の最小値 min s(i) 」を、最大化しなさい。
この問題は「満足度の最小値 min s(i) 」を最大化する問題なので、素直に考えると、スコア=「満足度の最小値 min s(i) 」としたくなりそうですが、これは良くありません。仮にそうした場合、
状態A s(0)= 10, s(1)=10, s(2)= 10 のとき、スコアはmin{s(0),s(1),s(2)} = 10
状態B s(0)=1000, s(1)=10, s(2)=1000 のとき、スコアはmin{s(0),s(1),s(2)} = 10と状態Aと状態Bのスコアは同じになってしまいます。これはスコアは同じといえ、状態Bのほうが明らかに良い状態です。なぜなら、s(1)の点が仮に300点に増えたとしたら
状態A' s(0)= 10, s(1)=300, s(2)= 10 のとき、スコアはmin{s(0),s(1),s(2)} = 10
状態B' s(0)=1000, s(1)=300, s(2)=1000 のとき、スコアはmin{s(0),s(1),s(2)} = 300と状態Bのほうは一気にスコアが増えます。しかし元のスコア関数のままだと状態Aと状態Bは同じスコアで、状態A→状態Bはスコア改善になりません。つまり焼きなまし法を行っても、状態A→状態Bには運が良くないと移動しません。
この問題であれば、例えば、
スコア=1番小さいs(i) + 0.0001 * 2番目に小さいs(i)
とすれば
状態A s(0)= 10, s(1)=10, s(2)= 10 のとき、スコアは 10 + 0.0001 * 10 = 10.001 状態B s(0)=1000, s(1)=10, s(2)=1000 のとき、スコアは 10 + 0.0001 * 1000 = 10.1
と状態Bの方が好スコアになり、状態A→状態Bに移動しやすくなります。
ここは問題によって大きく有効かどうか大きく異なってきますが、必ず考慮に入れたほうがいいでしょう。結果に大差がつきやすいポイントです。
★★★スコアが改善しやすくなるようなスコア関数を決める。
上記の言い換えともいえるのですが、わりと焼きなまし法のスコア関数をつくるときに、問題のスコア関数をそのまま使ったり、違う状態を正しく評価しなかったりすると、同じスコアになりがちで、青い線のような飛び飛びの平坦な関数になることが多いです。赤いように、山登りしやすいスコア関数を作れないか考えましょう。必ずしも、問題のスコア関数の最大値と、焼きなまし法で使うスコア関数の最大値が一致する必要はありません。最大値をとりうるような状態(argmax)を一致させることが重要です。

★★★スコア増分が0のときを、無くす。
2021/03/06 追加しました。
スコア増分が0のときは、焼きなまし法をやっても状態が行ったりきたりブラウン運動するだけで、解がなかなか改善しません。また、遷移するときの処理のほうが遷移しないときより重くなる場合、さらにひどいことになります。必ずスコア増分の履歴をチェックし、スコア増分が0になっているときはスコアの差をつけましょう。
★★★ 制約条件がある問題では、スコア関数にペナルティをつける。
2021/03/06 追加しました。
制約条件がある問題で、「制約条件を満たさない状態への遷移を許さない」とすると、ほとんど状態遷移されないままになってしまうことがあります。こういうときの対策としては、制約を満たしていない解も許して、ペナルティをつけて、スコア関数から減点します。
- 制約条件を満たしている度合いがひどいほど、ペナルティは大きく減点します。
- 計算の序盤ではペナルティは小さく、徐々にペナルティを大きくして、最後には絶対に制約条件を満たすようにします。
- 最後にでてきた最適解が制約条件を満たしているか確認しましょう(ただ、そうならないようなペナルティのつけ方を見つけるのが理想です。)
4. 遷移確率と温度
たいていの焼きなまし法の解説書には、expを使った方法が載っています。
焼きなまし法 - Wikipedia
遷移確率 P(e, e' , T) は e' < e の時に 1 を返すよう定義されている(すなわち下りの移動は必ず実行される)。
そうでない場合の確率はexp((e−e' )/T) と定義
注:wikipediaの引用なので、本文の設定と違います。
ここでのTは温度(=時間とともに減っていく値)です。
最小化問題なのでe−e'となってます(最大化問題ならe'-eです)。
★時刻tに置ける温度Tを調整する
最初の例の以下のコードの部分です。
const bool FORCE_NEXT = R*(T-t)>T*(rand()%R);
上の例だと、
- t=0のとき、常にtrue
- t=Tのとき、常にfalse
になるような線形関数にしています。だいたいの場合は、これで問題ありませんが、バリエーションはいろいろ考えられます。実際には、ベストスコアの更新状況をみて、更新があまりに序盤と終盤に固まっているときは、2乗してみるとか、ロジスティック曲線をつかうとか、その程度で良いと思います。
★★★★exp(e-e')/Tを使う。(e-e':スコアの悪化量)
wikipediaでは以下のように書いていますが、exp(e-e')/Tの形にしたほうが良いでしょう。(理由は、次回の改定時に書きます)
関数 P は e' −e の値が増大する際には確率を減らす値を返すように設定される。 つまり、ちょっとしたエネルギー上昇の向こうに極小がある可能性の方が、 どんどん上昇している場合よりも高いという考え方である。しかし、この条件は 必ずしも必須ではなく、上記の必須条件が満たされていればよい。
ただ、このexpの式、分子はスコア差なので分かりますが、分母の温度をどう決めれば良いかは分かりづらいです。目安としては、たまには許容しても良いスコアの悪化量を温度とすると良いです。 最大の山を越えられるようにと考えると、考えられるスコアの最大値-最小値を初期温度を設定したほうが良いのですが、実際には温度調整して最終スコアがどうなるか実験してみてください。
double startTemp = 100; double endTemp = 10; double temp = startTemp + (endTemp - startTemp) * t / T; double probability = exp((nextScore - currentScore) / temp); // 最大化なので、分子はnextScore - currentScoreで良い。 bool FORCE_NEXT = probability > (double)(mXor.random() % R) / R;
時刻t=0(最初)でtemp=startTemp、時刻t=T(最後)でtemp=endTempとなります。
例えばスコアが100悪化したとき、nextScore - currentScore = -100なので、startTempを100にしてみます。endTempはとりあえず10にしてみましょう。
時間t=0であれば、exp(-100/100) = exp(- 1) = 0.36787944117と、3回に1回ぐらいは遷移します。
時間t=Tであれば、exp(-100/ 10) = exp(-10) = 0.00004539992と、まず遷移はしません。
このような感じでやると、良いと思います。
5. アレンジ
★★★★ 山登り
最初の例をFORCE_NEXT=0にすれば、山登り法になります。そもそも関数が凸であれば、山登り法も焼きなまし法も結果は一緒で、しかもrand()を使わない分、山登り法のほうが高速で、スコア改善のチャンスも多くなります。簡単に試せるので、試しましょう。
★ 多点スタート
焼きなまし法をつかっても、局所解にはまりやすい場合は、初期値を毎回かえた、多点スタートにする方法もあります。山登りと同時に使う方法もあります。ただ、多点スタートで結果がよくなるケースは、そもそもスコア関数や近傍が良くないので、そこを見直したほうがよいかもしれません。
★★★ 1変数ごとに焼きなまし
焼きなまし法で、たとえば、y = f(x1,x2,x3,x4,x5)と、状態変数が多いとき、次の状態のパターンが多くなり、結果的にあまり多くの状態を試せず、良い解が求められないときがあります。このような場合は、x2=x3=x4=x5を固定して、x1を焼きなまし、x1=x3=x4=x5を固定して、x2を焼きなまし、x1=x2=x4=x5を固定して、x3を焼きなましというふうに1変数ずつ焼きなまししていく方法があります。xの値がそれぞれ独立性が高い(?)場合は、この方法は有効です。
6. デバッグ
★ スコア差分の検算
2021/03/06 追加しました。
例えばサンプル2ではスコアの差分を計算していますが、いきなり書くとバグらせる可能性もあります。以下のような手順をとれば、バグがないか確認することができます。
- サンプル1のgetFullScoreのように、全体のスコアの関数を用意して、それが正しいか確認します。通常のコンテストなら提出することで確認できます。
- 差分スコアrealDeltaScore = getFullScore(遷移後) - getFullScore(遷移前)として計算します。
- サンプル2のようにdeltaScoreを直接求める方法ができたら、realDeltaScoreと一致するか確認します。
★ デバッグの際には、決定的にする
2021/03/06 追加しました。
状態やスコアが、まれにおかしくなるといったバグがあった場合、通常の焼きなまし法は非決定的なのでバグが再現ができない場合があります。そういったときは、デバッグ時には決定的にしましょう。
- 温度を求めるときにsystem clockを使わずに、最大ループ回数を固定して進行割合で温度を求めるようにしましょう。
const static long long MAX_STEPS = 10000000; // 終了までの回数 for (long long steps = 0; steps < MAX_STEPS ; steps++) // 試行回数 { const double progressRatio = static_cast<double>(steps) / MAX_STEPS; // 進捗。開始時が0.0、終了時が1.0 temp = START_TEMP + (END_TEMP - START_TEMP) * progressRatio;
- 乱数はシードさえ固定すれば決定的になるので問題ありません。
- もしマルチスレッドを使っている場合は、グローバル変数とstatic変数に気をつけましょう。とくに乱数でstaticを使っている場合は乱数をクラス化するか、シングルスレッドで実行しましょう。
7. まだ書いていない内容
- 並列化
- 排他制御つきの焼きなまし
- ロックフリーの焼きなまし
- タブーサーチ + 焼きなまし
- レプリカ交換法
リンク集
基礎編
AtCoder wataさんによる公式解説
https://img.atcoder.jp/intro-heuristics/editorial.pdf
Tsukammoさんの記事
qiita.com
gacinさんの記事
gasin.hatenadiary.jp
応用編
ats5515さんは、巨大近傍法(状態遷移の回数は少なめになるけど、計算時間をかけてより良い次の状態を探す)が特に強いです。近傍の計算時間に。焼きなまし法の近傍を探すのに2段目の焼きなまし、制約条件をほぼ満たす準validな状態、温度遷移の工夫など、他の人があまり工夫しないもところでもいろいろバリエーションがあります。
ats5515.hatenablog.com
hakomoさんの記事は、まさに詳細という内容です。探索空間の話は、この記事が一番詳しいと思います。事例へのリンクも多いです。
github.com
HACK TO THE FUTURE 2019予選の反省
beta.atcoder.jp
7位/519でした。
今回は、意地でも定番解答にはならない問題をchokudaiさんが作ってくるかなと思ったら、わりと定番だった。見えることを1つ1つ改善していけば、点が増えていきやすいタイプ。
…と思いきや、後半に、いろいろ考察をちゃんとしてれば、加点できる要素があったので、上位から下位まで、実力が出やすい問題だった気もする。
tsukammoさん、chokudaiさん、ありがとうございました!
良かったこと
- 天才解法を考える誘惑に負けず、簡単なところから行ったのが良かった。
- 決勝に出れないのは分かっていたけど、ちゃんと最後までがんばった。もう衰える一方の年齢なので、老化防止のために、がんばるべきときにがんばるのは重要。
反省すべきこと
- 残り2時間で伸びなかったのだけど、条件が変わった後の再考察が足りなかった気がする。
- 焼きなまし法のマスの状態遷移の調整(開始5時間経過あたり)で、"#TD"はいらないということに気づく。ここで、TD#がなくなったことで問題の条件が大きくかわったので、高速化できる要素等がないか改めて考えるべき。今回の場合、TD#がなくなったことにより、命令Sはマスが.LRどれでも直進1歩になったので、マス変更の影響がなくなる。
- 2Dフィールドで、何かを動かすというのは、マラソンマッチでは定番。それなのに、経路を圧縮するのを思いつかないのは、ダメ。
- せめて焼きなましの温度調整は、自動化したほうが良かった気がする。30ケースで軽いからと、自動化しなかった。
- 一部ソースコードが大変に汚い(ムダなif文など)。コード汚いと、基本遅いし、また、いろいろ試すのをためらう原因になるので、ちゃんと書きましょう。
解法
マスを'..LR'の割合で遷移させる焼きなまし法。10万ループぐらい。5度→0度で線形変化。評価関数はスコアのまま。
やったこと
- 変更マスを通ったロボットだけ、経路を更新する。
- ロボット経路を保存して、ロボットの途中位置から計算
- マスは1次元配列で持つ
- 遷移状態の調整。TD#を使わない。
- 焼きなまし、変化スコアが悪くなったら計算途中早期打ち切り。
- わりと重要テクニックで。これで焼きなまし回数が2万→10万ぐらいまで増え、13万到達。
やったけどボツ
- 中央付近にLR少なめ
- 中央付近はあまり変えない
- ロボット0の箇所の評価点を、最初は高めに
- 初期盤面を、高スコアのときの割合の'L''R'に合わせて配置
やらずにボツ
- ロボットが4個・5個重なるケースにわずかに加点。そもそも、初期状態でも、ほぼ4,5がなかった。でも、やって損はなかったのでは。
- 'S'の数の偶奇でロボットを分ける(壁にぶつかると無意味)
気づかなかったこと
- 移動コマンドの圧縮。
- 変更マスを通り、回転するロボットだけの経路を更新する。(上記の説明)
- 初期L盤面。
hakomoさんの解析なるほどじゃ。
— nico_shindannin (@nico_shindannin) 2018年11月12日
ロボットをバラバラにする問題だから、最初からバラしていくのが良く、LRはむしろ悪いマスぐらいに思っていたのじゃ。
最終的にバラければいいし、ロボットの途中の場所はあまり重要でないので(最後にバラければ良い)、速度の恩恵のほうがでかいのか #HTTF
- kimiyukiさんの解答によると、「中央にDで縦棒を引いて土管のようなものを作るとLが実質小さくなるので速い」。kimiyukiさん、面白い形状をつくった改善が得意な印象があります。
最重要
復習しないとムダ。復習しないとムダ。復習しないとムダ。
Marathon Match 100 のゴミメモ!
下書きで終わっていた記事が、残っていました。ゴミメモのままでしかないのですが、脱線に至るまでの経緯が、今見るとおもしろかったので、そのまま投稿。
50位以内だと、懐かしの旧TopCoder時代のTシャツがもらえるマッチでした。まだ現役なので、老兵どもに負けるわけにはいかないのじゃ!
結果:76位/280(遠くへ行きたいです)
最初のメモ(開始2日目)
当時のメモで、あまりよく覚えてないのですが…。
ファーストインプレッション
- 近くからしかとらない・縦しかとらない・横しかとらないという条件であれば、いろいろできる
- 斜めどりはかなり難しい。
- ダイヤに穴をあけるようにしても、端からきれいにとっても、取れる箇所はほとんど増えない。
- とったことにより、どれが取れるようになるかの分析が最重要。
- 距離を限定して焼きなましするアイディアは面白いかもしれない。ただ後半の焼きなましは疑問。
- ビジュアライザ、最終的にどれとどれをペアで取ったのかは、見たいかも。
- 無害でとれる
- ハマり形(はまり形を事前に知ってれば、避けたり、評価値に入れたりすることも可能。)
- 焼きなまし解法。
- 遅延セグ木
なんか、うまい取り方を考えようとしてたっぽいですね!(なんで遅延セグ木と書いてるんでしょう…)
反省点:ファーストインプレッションの前に簡単な解法を提出せよ!!
まず、この問題のポイントとして、ほとんどのケースで全部とれます。最初に簡単にそれに気づくはずなのに、その条件なしで考えはじめると、複雑な条件で考えないといけなくなります。無駄に時間がすぎる。
あ、でも、いつも簡単な解法をやらずに失敗しているので、今回は絶対に簡単な解法を書こうと思ったんですよ。でも、なぜか感覚が麻痺していて、
- せめて貪欲法で書きたいなぁ
- なんらかの評価関数がほしいなぁ
- これは取れる個数ができるだけ多くなるように
- めっちゃ重くならない?
- というか、これはどこから取るのがいいんだろう?
- 考察へ移行
という感じで、簡単な解法すら思いつかず、なんか脱線するわけですね、自分をコントロールできない!すでに自我がない!あなたの生きている意味は?
そういうときは、ランダム!O(1)で最強!!
というか、超簡単な解法リストでも作って、機械的にやったほうがいいような気もしてきました。思いつかないんだから。
ファーストインプレッションの前に、簡単な解法
ランダムでとるのが思いつかないんですね…簡単な解法
(ビームサーチ解は捨てる!)
焼きなまし法(最終日)
評価関数
- 解決されていないやつは、後半にとるやつのほうが被害が少ない。
- エリアが広いこと自体をマイナスとしてもいいかも。(すぐに他のやつが入りこむので)
評価差分
囲われフラグは、orderは無視したもの。
- 全盤面評価はひどいので直す。
- Swap Pos -> それぞれのRectごとに、スコアをキャッシュしておく。Rect別再計算
→Orderも考えると、
→今囲んでいるやつ、各点の囲われフラグを解除
→新しく囲んだら、各点に囲んでいるフラグを追加
- Order change -> OrderをかえたRectの再計算。囲われているRectに対して+1,-1
点ごとに、囲われているRectを持つ必要がある。→これは問題!!!
- Order Changeはなしにして、定期的にOrder計算と最終結果計算を行う方法はあるかも。
面積でソートすれば、それなりに
- そもそも距離2のは無条件にとって良い。order無意味。
- Orderほんと必要?一意に決まるのに。
- 分割エリアごと orderなら毎回
- Forward形式に変更
近傍
- SwapOrderをChange Orderにする(orderはfloatかdouble)
- 移動をprogression ratioに合わせて、徐々に小さく(Swap Pos・Change Order両方)
- Posを移動面積距離が大きい順にソートして、近くしか移動
- だめな部分を狙って変更する?
温度管理
→ats式がよさそう。
大きい近傍
- 分割統治(やるなら、端からとったほうが良さげ)
わるあがき
- はじを優先的にとるランダム
- 後半単純に遅いかも。
- 失敗したやつを優先的のとるランダム(これは簡単なので、先にやっていいかも)
- 焼きなましの結果を使う
- 高速化版ランダムGreedy解法
- ランダム途中からスタート解法
初期解
- 最寄りペアからスタート
- 貪欲解からスタートのほうがいいのでは!?まぎれが少ないし、一定の得点は保証される。逆より全然良い。ただし、
TCO Announcement Fun Round - WaterfallFishingの反省
2017年5月の、ちょっと古いマラソンマッチですが、忘れないようにするために、書きました。
問題
https://community.topcoder.com/longcontest/?module=ViewProblemStatement&rd=16930&pm=14615
川の幅 W (2≦W≦200)
川の長さ L (5≦L≦100)
川には、岩がある。(5≦岩の数≦W*L/10)。ただし、岩の場所は、分からない。
まず、D日間連続で、魚が上流から下ってくる(4≦D≦20)。
- 5≦魚の数≦100
- 魚は、魚群の中心の位置M・標準偏差Sの正規分布で、まず上流に配置される。(0≦M≦W-1, 2≦S≦W/4)。M,Sも分からない。
- 魚はまっすぐ下るが、岩にぶつかると50%の確率で左に1マス、50%の確率で右に1マスずれて落ちる。
- 魚が、下流に下ってきた魚の数は、場所ごとに分かる。

(範囲になっている変数は、テストケースごとに、ランダムに均一に選ばれる)
D日間分の下流に下ってきた魚の数の情報を用いて、D+1日目に落ちてくる魚の場所を予測し、罠をしかけて、できるだけ多く捕れ。スコアは、(捕まえた魚の数)/(罠を仕掛けた数)で決まる。与えられた計算時間は60秒間。
方針
機械学習で予測した。ただ、この問題、データが足りなすぎる、かつ、あまり当てにならない。魚群の位置M,Sは毎日変わるので、ここの予想が外れると、ほぼ魚を捕れない。そういうわけで、機械学習は避けて、確率の知識などで解答した人が多かったっぽい。
ただ、自分は機械学習でごり押しした。データ不足を補うために、自前でデータを生成した。やり方は以下の通り。
(1) 「岩配置」と「下流に下ってきた魚の数のデータ」のペアを、問題と同じ方法で200種類生成。
(2) 「岩配置」から、下流に下ってきた魚の数の期待値を場所ごとに求める。上流の魚の確率分布は、1000万回シミュレーションして求めた(数学強い方なら解析的に求められる)。上流での魚の確率分布と岩の配置を用いれば、簡単な期待値DPで、下流に下ってきた魚の数の期待値を求められる。これを機械学習の目的変数(予測したい値)として使用。
(3) 「下流に下ってきた魚の数のデータ」は、機械学習の説明変数(特徴量)の生成のために使用。最終的には以下を説明変数として用いた。
- 下流の位置 X
- 川の幅 W
- 川の長さ L
- 魚の数
さらに、Xの近傍のデータも説明変数に追加した。近傍をY (X-3 <= Y <= X+3)として
- D日間で、Yに下ってきた魚の総数
- D日間で、Yに下ってきた魚の割合の和
- D日間で、Yに下ってきた魚の総数とXに下ってきた魚の総数の差
(4) あとは、自前のランダムフォレスト(そろそろ、自前Gradient Boosting系のものを用意しておきたい…)で50秒間訓練。
(5) 全ての位置Xで、下ってきた魚の期待値を予測し、もっとも期待値が大きい場所1か所に罠をしかけた。
まとめ
他人の解法と、自分の解法がズレてたおかげで、まさかの1位!機械学習しても2位のスコアとの差は大きくないのですが、不確定要素が多すぎるこの問題においても、機械学習が有効だったのは、自分でも驚いた。データ生成の仕方が重要。
実は、このマッチはあまり時間の余裕がなく、また直前のマラソンマッチのミスでレートを大きく下げていて弱気になり、参加する予定はなかったのだけど、tomerun氏の無言の煽り励ましツイートで、参加することになったのでした。マラソンマッチは、最後まで何が起こるかわからないので、皆さんも参加しましょう!
マラソンマッチの簡単な解法
まえがき
この記事は、Competitive Programming Advent Calendar 2017 - Adventar 18日目の記事です。
最近は、簡単にやるべきことでも、難しくやってしまうことが多く、それがマラソンマッチでの不振につながってるので、「簡単な解法」をネタに書きます。
昔、自分でこう言ってました。
敗因:誰でも思いつくようなケースをほとんど試さなかった。
特に、時間がかからずに実装できるものは、絶対試したほうがいいです。仮に全然結果がでなかったとしても、その後のヒントになる可能性もありますし、条件によっては使えるかもしれません。今回、自分の考えたのは実装時間がかかるため、それが外れ方針なのに気づくのに時間がかかってしまいました。
はい、その通りです。でも、その最初に作りたい簡単な解法が、年々思いつかなくなってきているので、復習しようと思います。マラソンマッチ初級者向けの記事です。
問題
Topcoder Marathon Match 95 CirclesMix を取り上げます。
- できること
- 好きな位置・大きさ・色の円を指定個数置けます。最初は真っ黒のフィールドで、円を置くと、(置いた円の色+フィールドの色)*2になります。
- 条件
- (平均的な条件は)円の数=500, 座標=0~500, 色赤青緑=0~256
- スコア
- 目標になる画像に近い画像を作った人が勝ち(スコアは、目標画素と作った画像の画素の絶対値の差の和で、低い程よい)。

以下は解法の例(アニメーション)です。
https://www.topcoder.com/contest/problem/CirclesMix/2.gif
{kind=link}
この問題のベストな解法はおいといて(MM 95 - Togetterを見て )、今は、最初に作りたい簡単な解法について、考えてみます。
簡単な解法(失敗例)
例えば、
「平面を4方向に動くロボットを動かして、落ちているコインを集めよ!」
という問題だったら、コインまでの近さをスコアにして、上下左右4方向について試して、もっとも高スコアな方向に動かすとかやれば、それなりに動くでしょう。これで良いと思います。
ただ、この問題で、貪欲で一番良い選択肢に、円を1つずつ置いていくといっても、とりうる選択肢が多いときは、計算時間が間に合わなくなりがちです。(「解空間が大きい」という人もいます)
貪欲法をそのままやるとすると、
for(int circle=0;circle<500;++circle) // 円の番号circle { // 円をスコアが最も上がるベストなところに置く。 for(int cy=0;cy<500;++cy) // 円の中心座標cy for(int cx=0;cx<500;++cx) // 円の中心座標cx for(int r=0;r<500;++r) // 円の半径 for(int R=0;R<256;++R) // 塗る色 赤R for(int G=0;G<256;++G) // 塗る色 緑G for(int B=0;B<256;++B) // 塗る色 青B { // 塗る点ごとに得点計算 int score = 0; for(int y=cy-r;y<=cy+r;++y) for(int x=cx-r;x<=cx+r;++x) { score += .... } } }
みたいなかんじのコードになって、forループの回数が、ざっくり500*500*500*500*256*256*256*500*500となり、ひどく重くて動かないわけです。そこで対策というか、適度な手抜きが必要になります。
簡単な解法(改善例)
1.ランダム
ランダムは速い、何でも計算量O(1)にするので、すごい。この問題だったら、最初にやるべきです。
for(int circle=0;circle<500;++circle) // 円の番号circle { // 100箇所試して、スコアが最も上がるベストなところに置く。 for(int turn=0;turn<100;++turn) { cy = rand()%500; cx = rand()%500; r = rand()%500; R = rand()%256; G = rand()%256; B = rand()%256; // 塗る点ごとに得点計算 int score = 0; for(int y=cy-r;y<=cy+r;++y) for(int x=cx-r;x<=cx+r;++x) { score += .... } } } }
これだけでも、ループ回数は500*100*500*500と激減します。解は良くないですが、簡単に書けますし、最初の解法としてはアリだと思います。
2.固定
ばかげていると思うかもしれませんが、この問題であれば、円の半径rについては固定でも、それなりの解は作れます。まずは簡単な解でいいので、固定も全然ありです。
3.粗くする
問題の特性上、粗くしても(画像を縮小して、色調も減らす)、それなりの解がでそうです。例えば、すべてではなく、10おきに調べるようにすれば
for(int circle=0;circle<500;++circle) // 円の番号circle { // 円をスコアが最も上がるベストなところに置く。 for(int cy=0;cy<500;cy+=10) // 円の中心座標cy for(int cx=0;cx<500;cx+=10) // 円の中心座標cx for(int r=0;r<500;r+=10) // 円の半径 for(int R=0;R<256;R+=10) // 塗る色 赤R for(int G=0;G<256;G+=10) // 塗る色 緑G for(int B=0;B<256;B+=10) // 塗る色 青B { // 塗る点ごとに得点計算 int score = 0; for(int y=cy-r;y<=cy+r;++y) for(int x=cx-r;x<=cx+r;++x) { score += .... } } }
これだけで、10*10*10*10*10*10の1000000倍速くなります。もちろん解は悪くなるのですが、最初は粗くして速攻でイマイチな解を求めて、その解の結果を生かして、重要な部分を徐々に細かくしていくという方法も有効です。
簡単な解法(あまり簡単ではない例)
4.独立させる
この問題、得点計算の部分、色R,G,Bは独立していました。そういう場合、バラで計算すればforループをバラすことができます。
for(int circle=0;circle<500;++circle) // 円の番号circle { // 円をスコアが最も上がるベストなところに置く。 for(int cy=0;cy<500;++cy) // 円の中心座標cy for(int cx=0;cx<500;++cx) // 円の中心座標cx for(int r=0;r<500;++r) // 円の半径 { for(int R=0;R<256;++R) // 塗る色 赤R { int scoreR = 0; for(int y=cy-r;y<=cy+r;++y) for(int x=cx-r;x<=cx+r;++x) { scoreR += .... } } for(int G=0;G<256;++G) // 塗る色 赤G { int scoreG = 0; for(int y=cy-r;y<=cy+r;++y) for(int x=cx-r;x<=cx+r;++x) { scoreG += .... } } for(int B=0;B<256;++B) // 塗る色 赤B { int scoreB = 0; for(int y=cy-r;y<=cy+r;++y) for(int x=cx-r;x<=cx+r;++x) { scoreB += .... } } }
解は同じですし、計算量は256*256*256⇒256と、1/65536になります。いつでも使えるわけではないですが、独立している要素がないかチェックしましょう。
5.前の計算結果を再利用
以上のケースでは、スコアを毎回1から計算していましたが、例えば、半径や塗る色などそのままで、cxとrを+1大きくするとしましょう。ほとんどの範囲は被るので、その範囲の計算は端折ることはできるはずです。下図左のcxを+1大きくする場合は、青い部分を足し、赤い部分を引く。下図右のrを+1大きくする場合は、青い部分を足すだけです。紫の部分は再計算する必要はありません。

または、差分(微分)は前計算でき、メインの計算量に影響を与えないことも多いです。それぞれの変数に対しての差分を一度は検討してみましょう。これは貪欲法だけではなく、焼きなまし法などの近傍を高速に求めるときにも有効です。
6.部分的な最適化
もし部分的にでも最適解が総当たりよりも高速に出せるのであれば、それで計算量を減らすことができます。この問題、実は、円の位置cx,cyと円の半径rが固定であれば、色RGBの最適解は、円の範囲内で(2*目標画像-現画像)についてのヒストグラムをつくり、色の中央値が塗る色の最適解となります。(ヒント:スコアを塗る色で微分し、それが0になるところが最適解。微分のかわりに塗る色を+1するとスコアがどう変化するかを考えるとわかる)
そのほかにも、二分探索・三分探索・動的計画法などSRMで使えそうなアルゴリズムも考慮するといいです。焼きなまし法などの最適化アルゴリズムも高速化の手段の1つですが、最初の簡単な解法とは、だいぶ離れてしまうので、まずは1~5を考えてみてください。
(重要:他にも、こういうのがあるよというのがあったら、教えてください!)
まとめ
というわけで、貪欲法を実現するにも一苦労です。でも、解は悪くてもいいので、最初の解法までは、早くたどり着いたほうがいいと思います。
なお手法は6種類だけだとしても、何に対してどの手法を適用するのかと考えると少なくありません。少し例を挙げただけも、いくらでも作れそうなのが分かると思います。
- 円の位置cx,cyと半径rは粗くして、色RGBだけランダムを使う。
- RGBはforループでまわして、円の位置cx,cyと半径rについてのみ最適化アルゴリズムを適用。
- 円の半径rは固定して、円の位置cx,cyはforループですべて試す、色RGBについて部分的な最適化。
上位者が「解法は、〇〇はランダムで△△は貪欲でした」と簡単に言ってたとしても、そこに至る過程でいろんな選択肢があったうえでベストなのを選んでいるわけで、決してそこは簡単ではないんですね…。
あとがき
それがマラソンマッチの奥の深さ・難しさ・楽しさでもあるので、ぜひみなさんも参加しましょう!最近のですと、
- AtCoderのWeathernews Programming Competition - Weathernews Programming Competition | AtCoder 2017年12月15日正午から2018年1月15日正午まで
- Topcoderの Marathon Match 96 2017年12月21日11:00から28日11:00まで。
などがあります。
明日の12/19のCompetitive Programming Advent Calendar 2017 - Adventar は、shisashiさんの「競プロ用に作成したエディタのプラグインを紹介します」です。楽しみですね。それでは、また!